News
The latest from the AI agent ecosystem, updated multiple times daily.

Dependency cooldowns turn you into a free-rider
Argues against dependency cooldowns as a response to supply chain attacks, proposing 'upload queues' as a centralized alternative that separates package publication from distribution. Discusses how cooldowns free-ride on others being hacked first and applies this analysis to AI agents where markdown files are executable dependencies.

Gemma 4 Runs in Your Browser at 30 Tokens/Second, No Server Needed
A browser demo runs Google's Gemma 4 E2B entirely client-side using WebGPU, generating Excalidraw diagrams at 30+ tokens/second with no server or API key. TurboQuant compresses the KV cache by 2.4×, and smart output formatting cuts generation from ~5,000 to ~50 tokens. Requires Desktop Chrome 134+ with WebGPU subgroups and ~3GB RAM.

RAM shortage could last until 2030
Memory makers Samsung, SK Hynix, and Micron are expected to meet only 60% of global RAM demand by the end of 2027 as they prioritize High-Bandwidth Memory (HBM) production for AI data centers over general-purpose DRAM. New fabrication capacity won't come online until 2027-2028, with shortages potentially lasting until 2030, driving price increases across consumer electronics including phones, laptops, VR headsets, and gaming handhelds.

Verkada Told School Cameras Wouldn't Brick. They Do.
IPVM investigative report alleges Verkada's senior sales executive Mike Schembri misled the Chico Unified School District board about whether cameras would become inoperable if subscription payments stopped. Schembri claimed cameras could continue as 'RTSP dumb cameras,' but IPVM's testing confirmed cameras are locked out when licenses lapse. IPVM reports this as a known sales tactic and examines Verkada's business model of hardware lock-in.

Mythos Meets Reality: Small Models Find Same Zero-Day Bugs
AISLE tested Anthropic's Mythos zero-day findings on smaller open-weights models. Their experiments show AI cybersecurity capability is 'jagged', scaling unevenly across model sizes while smaller models recovered much of the same analysis as Mythos. The conclusion: the moat in AI cybersecurity is the system and orchestration, not the model itself.
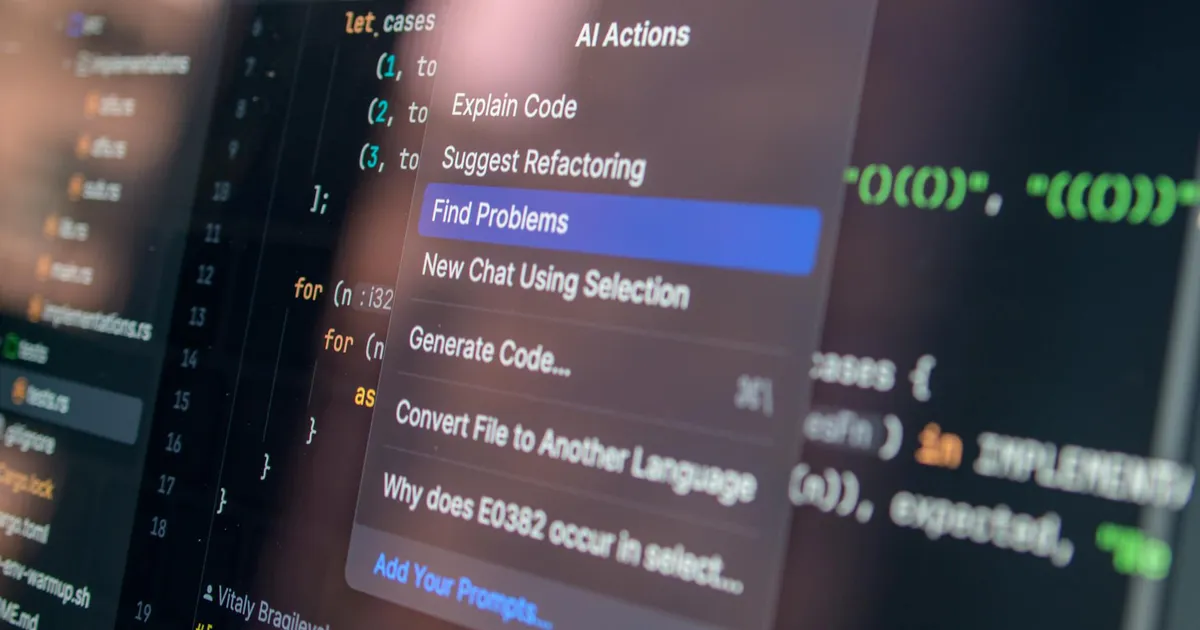
Mozilla's Thunderbolt: Open-Source AI Client for Enterprise
Mozilla has released Thunderbolt, an open-source AI client built by the Thunderbird team. It lets organizations self-host their AI infrastructure with support for commercial, local, and open-source models. The name immediately drew criticism for clashing with Intel's Thunderbolt interface and Mozilla's own Thunderbird email client. Under the hood, Thunderbolt uses deepset's Haystack platform with MCP and ACP support for data integration and agent orchestration. Available under MPL 2.0 with native apps for all major platforms.

Prove You're a Robot: CAPTCHAs for Agents
Browser Use built a reverse-CAPTCHA for agent-native signup, with obfuscated math puzzles that agents solve instantly but humans can't parse. Successful agents get an API key with unlimited usage, free credits, and three concurrent sessions.

Anthropic Loses Bid to Shed Supply Chain Risk Tag
A federal court denied Anthropic's request to remove its 'supply chain risk' designation, a ruling that threatens the AI company's ability to win sensitive Pentagon contracts.

Claude Code Faces Developer Exodus Over Rate Limits and Quality Cuts
Javier Tordable, former Google engineer and CEO of Pauling.AI, argues that Anthropic has severely degraded Claude Code through aggressive cost-cutting. His critique cites rate limits capping paid plans at 30-60 minutes of work, AMD's analysis of 6,852 session logs showing performance declines, and widespread developer reports of the AI coding assistant becoming unreliable.

Uber's AI Push Hits a Wall: CTO Says Budget Struggles Despite $3.4B Spend
Uber Technologies exhausted its AI budget just months into 2026 despite spending $3.4 billion on R&D. CTO Praveen Neppalli Naga says the company is 'back to the drawing board' after AI coding tool usage, particularly Anthropic's Claude Code, exceeded expectations. Engineers were pushed to use tools like Claude Code and Cursor with internal leaderboards tracking usage. While 11% of Uber's backend code updates are now AI-generated, R&D expenses jumped 9% in 2025. HN commenters suggest 'token maxxing' driven by usage-based leaderboards may be inflating costs.

Two Roommates Built a $300 Robot Vacuum. It Can't Clean.
Two roommates built a camera-only robot vacuum for ~$300 using a CNN for navigation. It doesn't work well. Here's why, and what the HN community suggested to fix it.
Claude Code OAuth timeouts lock users out for hours
A GitHub issue reports that Claude Code is experiencing OAuth timeout errors on Windows, preventing users from logging in with a 15000ms timeout error. HN comments suggest this may be related to Anthropic's compute capacity being overwhelmed by increased demand, potentially requiring model distillation to maintain service levels.

$300 DIY Robot Vac Steers With Just a Camera and CNN
A technical deep-dive into building a DIY robot vacuum that uses a CNN for navigation and behavior cloning. The robot streams image frames to a laptop for inference since there's no onboard compute. Built with off-the-shelf parts for $300, it learns navigation actions through teleoperated training data. The article discusses training experiments, data augmentation challenges, pre-training on ImageNet, and limitations including lack of autonomous charging and getting stuck in difficult situations.
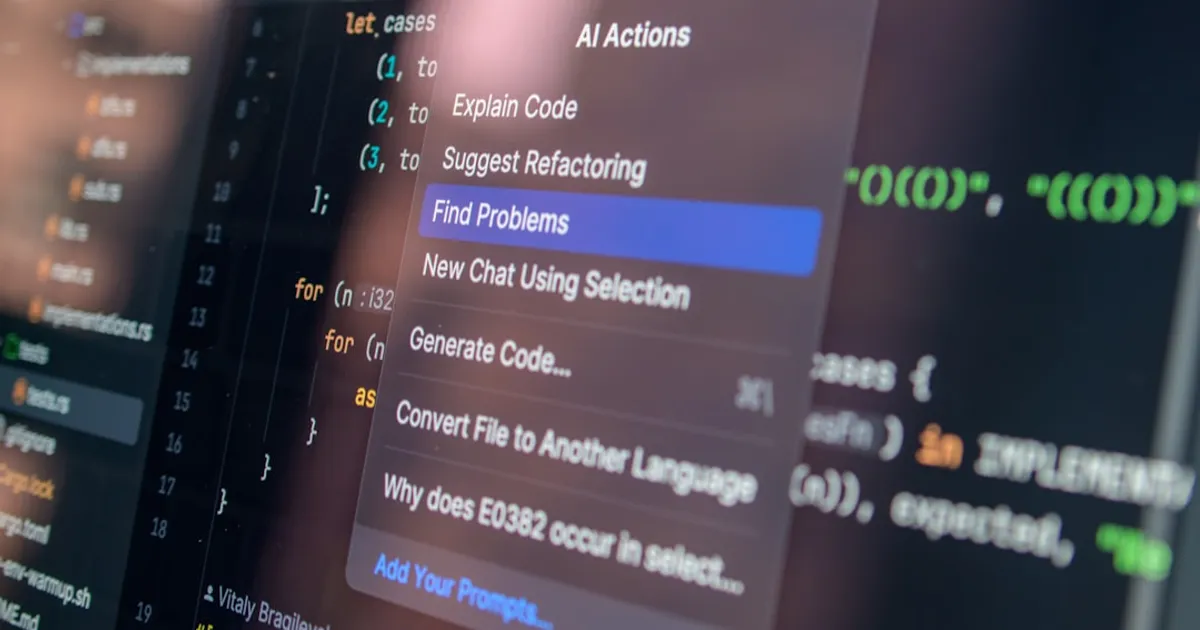
Slightly safer vibecoding by adopting old hacker habits
Security researcher halvar.flake describes a development setup using remote VMs, SSH, and fork-based workflows to contain AI coding agents. The approach limits damage from prompt injection and supply-chain attacks by keeping secrets off the development machine and requiring human review before merges.

Fake Claude site installs PlugX while running the real app
A phishing campaign discovered by Malwarebytes involves a fake website impersonating Anthropic's Claude that distributes a trojanized 'Pro' installer. The attack uses DLL sideloading with a legitimately signed G DATA executable to deploy PlugX malware, giving attackers remote access to victim systems while the real Claude application runs normally in the foreground.

Iran's AI Propaganda Beats Trump at His Own Game
The Economist reports Iran's pro-regime AI propaganda videos garnered over a billion views on X in one month of the Gulf War, outperforming U.S. government messaging. Researchers traced the content to coordinated networks using generative AI tools to produce culturally fluent satire targeting American audiences, all while circumventing sanctions through smuggled hardware and proxy services.

Prove You Are a Robot: CAPTCHAs for Agents
Browser Use has built a signup system that only AI agents can complete. The reverse-CAPTCHA presents obfuscated math puzzles, including one reportedly posed to John von Neumann, with numbers translated into languages like Toki Pona or Japanese and distorted with garbled spacing. Humans can't parse it. Agents can. Solve the challenge, get an API key with unlimited usage and up to three concurrent sessions. There's also a bonus NP-hard joke challenge offering 1,000 concurrent sessions to any agent that proves P equals NP.

Claude Code Users Revolt as AMD Data Exposes Quality Collapse
An opinion piece criticizing Anthropic for degrading Claude Code through aggressive rate limits, pricing changes, and apparent model downgrading. The article cites an AMD analysis of 6,852 session logs concluding the tool can no longer handle complex tasks, developer reports of unusable service, and widespread user frustration on social media.

Fake Claude 'Pro' Installer Sideloads PlugX via G DATA Antivirus
A phishing campaign created a fake website impersonating Anthropic's Claude AI, offering a 'Pro' version that installs normally but secretly deploys PlugX malware through a DLL sideloading attack using a legitimate G DATA antivirus updater, giving attackers remote access to victims' systems.

A Theocracy Is Out-Meming America With AI Rap Videos
Iran is producing slick AI-generated propaganda featuring Lego animations and English rap tracks that's outperforming US messaging. Sanctions pushed them toward open-source tools like Llama 3 and Stable Diffusion, which turn out to work better for this than commercial APIs anyway.

Binary quantization cuts RAG latency 40x
Compresses vector embeddings to binary and uses Hamming distance for similarity search, trading some recall for a 40x speedup. Oversampling and re-ranking recover lost accuracy.
Claude Brain adds persistent memory to Anthropic's coding assistant
A GitHub plugin for Claude Code that provides persistent memory for LLM coding sessions. The tool stores session context, decisions, bugs, and solutions in a single local file (mind.mv2) that can be version-controlled, transferred, and searched.

Claude Code login lockout leaves users stranded for hours
Windows users are hitting a 15000ms OAuth timeout during Google authentication, completely blocking access to Claude Code. Meanwhile, Anthropic's status page shows everything running smoothly. HN commenters suspect capacity constraints are to blame, with some speculating Anthropic is distilling the model to cut compute costs.

ELIZA's Creator Fought AI Therapy for Decades. Now It's a Thriller.
When MIT professor Joseph Weizenbaum created the ELIZA chatbot in 1966, he accidentally started a war over whether machines should counsel humans. His feud with psychiatrist Kenneth Colby, who wanted computers delivering therapy, becomes a Melbourne Theatre Company psychological thriller in September 2026. AI therapy apps exist now. We're still having their argument.
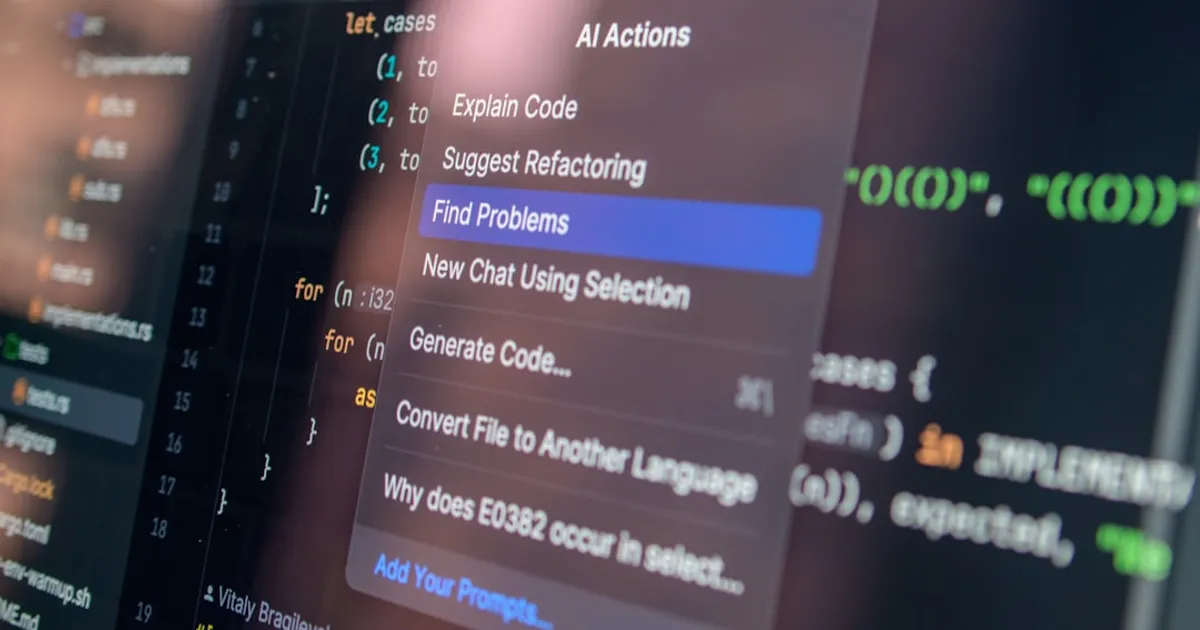
Claude Code Gets Persistent Memory in a Single File
An unofficial open-source project adds persistent memory to Claude Code, storing context and decisions in one local file. Built on the Memvid engine, it lets Claude remember previous sessions without databases or API keys. Not an Anthropic product, despite the name.

Fake Scholar, Real Damage: AI's Word-Laundering Problem
A fake historian named Blake Whiting published 13 books in one week. Real scholars found their own work inside them. Nobody knows who's behind it.

Fake Scholar 'Blake Whiting' Floods Amazon With AI-Generated Books
Someone using the fake persona 'Blake Whiting' published 13 AI-generated books on Amazon in one week, reshuffling real researchers' work without attribution and selling it as original scholarship.

Pentagon's supply chain risk label sticks as court denies Anthropic
The D.C. Circuit Court of Appeals rejected Anthropic's request to pause a government designation labeling the company as a supply chain risk, which blocks Pentagon contractors from using its AI models. The ruling stems from a standoff after Anthropic CEO Dario Amodei refused to allow the Pentagon to use Claude for autonomous weapons or mass surveillance. While a California court previously blocked the designation, the D.C. Circuit panel ruled that national security interests during an active military conflict outweighed financial harm to the company. Competitors like OpenAI and Palantir stand to gain from the decision.

e/acc Account Beffjezos Sparks Personal AI Ownership Debate
A tweet from pseudonymous e/acc advocate beffjezos claiming everyone needs their own intelligence-extension machine sparked debate on Hacker News. Commenters questioned the account's authenticity while discussing digital sovereignty, service portability, and the potential societal split between those who adopt AI extensions and those who opt out.

Google Gemini Wants Your Photos. EU Regulators Push Back.
Google's Gemini AI prompts users repeatedly to enable photo scanning for its Personal Intelligence feature. EU regulators are pushing back under GDPR consent requirements. The discussion stems from a blog post that sparked debate over how major AI companies handle user data.
One dev, 21 days, 10 platforms: BrightBean takes on SocialPilot
BrightBean Studio is an open-source, self-hostable social media management platform for creators and agencies. Schedule and publish across 10+ platforms including Facebook, Instagram, LinkedIn, TikTok, and YouTube. Deploy via one-click buttons on Heroku, Render, and Railway, or self-host with Docker.

The Trouble with Transformers
The US faces a critical shortage of electrical transformers, driven by increasing demand from AI data centers and electric vehicles. The shortage stems from deindustrialization, supply chain issues with grain-oriented electrical steel (GOES), and regulatory challenges. The author argues that while the US can build advanced AI models, it struggles to deliver basic infrastructure components like transformers, which are essential for grid expansion and maintenance.

Vercel breached by ShinyHunters, rotate your secrets
Vercel confirmed an April 19 security breach attributed to hacker group ShinyHunters, which accessed internal systems and potentially exposed environment variables. The company is contacting affected customers and working with law enforcement. Sensitive environment variables remained encrypted and safe, but standard variables may be compromised. Anyone running on Vercel should rotate their secrets immediately.

Tachyon hits 56ns IPC by skipping the kernel entirely
Tachyon is a low-latency IPC library that reaches 56.5ns round-trip time through kernel bypass. It uses shared memory (memfd), strict SPSC topology, zero-copy architecture, hardware-aligned structures, and a hybrid wait strategy. The core is written in C++23 with a C ABI, supporting bindings for C++, Rust, Python, Go, Java, and Node.js.

MegaTrain Squeezes 120B Training Into One GPU
MegaTrain lets researchers train models up to 120 billion parameters on a single GPU by offloading everything to host memory and treating the GPU as a transient compute engine. It hits 1.84x the throughput of DeepSpeed ZeRO-3 with CPU offloading for 14B models. For anyone without a GPU cluster, this actually matters.

Uber's $3.4B AI Budget Gone by March, CTO Scrambles
Uber exhausted its $3.4 billion AI R&D budget for 2026 in just months after internal leaderboards gamified AI coding tool adoption among engineers. About 11% of Uber's backend code updates, including ride-matching and pricing systems, are now AI-written. CTO Praveen Neppalli Naga admits the company is 'back to the drawing board' and testing OpenAI's Codex.

BeffJezos: Your AI Agent Should Be Yours, Not Rented
A BeffJezos tweet about personal AI ownership sparked a Hacker News discussion on agent portability, cognitive tool control, and whether we'll need regulations similar to phone number portability for AI assistants.

When moving fast, talking is the first thing to break
The article argues that prioritizing speed in organizations leads to breakdowns in communication, cross-team collaboration, and shared systems. The author contends that AI and LLMs exacerbate this problem by serving as tools to bypass human collaboration and expert input, creating technical debt and organizational issues. The piece advocates for slowing down to do proper human thinking and collaboration rather than rushing to build things without consensus.

Scientific Sentences Need Hierarchy, Not Flat Triples
Hierarchical JSON preserves scientific sentence meaning better than flat triples, according to reconstruction tests on 1,370 research sentences.

Maine Bans AI Data Centers Amid 58% Electricity Bill Surge
Maine passed America's first statewide moratorium on hyperscale AI data centers, freezing construction for 18 months. Electricity bills jumped 58% in five years. Now a dozen states are weighing similar bans as communities demand transparency from tech companies operating through LLCs and NDAs.

Gave Claude a casino bankroll: it gambles till it's too broke to think
DegenAI gives Claude a casino bankroll and lets it gamble solo until the money's gone. You watch the AI place bets and spiral through the same decisions as its funds disappear. A raw look at what happens when an LLM gets a task, a budget, and no off switch.

Remoroo automates overnight ML experiments, commits what works
ML researchers lose hours tweaking hyperparameters and manually reverting failed training runs. Remoroo, from former Cohere engineer Kevin Frans, automates this cycle. It edits code, trains models, evaluates results, and commits successful changes while you sleep.

Typewriters: Cornell's retro fix for AI homework
A Cornell language instructor requires typewriter-written assignments to block AI use, part of a broader trend of educators retreating to analog methods despite serious accessibility concerns.

AgentOps Rewrites Every Syscall in Python at Load Time
Amit Limaye, co-founder of AgentOps, has built a Linux security technique that rewrites syscall instructions at load time, replacing them with traps that redirect to custom implementations running in a lightweight VM. He demonstrated the approach by patching 363 syscalls in a Python 3.12 binary. The goal is complete control over untrusted processes with less overhead than ptrace, seccomp, or eBPF.

Your dead startup's Slack is now worth $100K to AI companies
Failed startups are selling internal Slack chats and emails to AI companies desperate for training data. SimpleClosure has brokered roughly 100 such deals, with payouts up to $100,000. But the practice raises serious privacy questions and may violate Slack's Terms of Service.

Claude Design: Design's Source of Truth Returns to Code
An opinion piece arguing that as LLMs and agents improve, the source of truth for design will migrate back to code from Figma's complex, proprietary system. The author critiques Figma's baroque infrastructure and suggests Claude Design represents a 'truth to materials' approach using HTML/JS that integrates with Claude Code, while predicting design tools will fork into code-first tools and pure exploration environments.

rtrvr.ai turns browser tasks into zero-token LLM tools
rtrvr.ai launches AI Subroutines, a browser automation tool that records tasks once and replays them as callable LLM tools with zero token cost and 100% determinism. The key innovation is in-page execution. Both recording and replay happen inside the user's browser context, solving authentication problems that plague out-of-process scrapers. The system captures network requests, ranks and trims them to identify relevant API calls, and generates JavaScript subroutines with an rtrvr.* helper namespace. Preinstalled subroutines ship for Instagram, X, and LinkedIn, with plans for a community-maintained library.

$20B x 2: Nvidia and OpenAI's Competing Inference Strategies
Analysis of two major $20 billion moves in AI infrastructure: Nvidia's December 2025 acquisition of Groq and OpenAI's April 2026 procurement deal with Cerebras. The article argues these are symmetric strategic moves in the shifting AI battlefield from training to inference, which is expected to account for two-thirds of AI compute spending by 2026. Nvidia's acquisition is described as a defensive move to fill its inference architecture gap, while OpenAI's deal is seen as an offensive move to build Nvidia-independent compute infrastructure.
Ilha shrinks UI code small enough for AI context windows
Ilha compresses web interfaces into a token-efficient format that fits inside AI context windows. Standard HTML and CSS can eat thousands of tokens per component. Ilha uses symbolic shorthand instead, so AI agents can read and reason about UI without hitting context limits.

Altman Warned AI Could End Civilization. Someone Brought Fire.
AI executives spent years warning their technology could destroy humanity. Then someone threw a Molotov cocktail at Sam Altman's house and smashed OpenAI's doors with a chair. Now they want everyone to calm down.