News
The latest from the AI agent ecosystem, updated multiple times daily.

Japan's Robots Fill Jobs Nobody Wants as Workers Vanish
Japan is deploying AI-powered robots across factories, warehouses, and infrastructure to address severe labor shortages driven by demographic decline. The government aims to capture 30% of the global physical AI market by 2040, with $6.3 billion committed to AI and robotics integration. Companies like Mujin, WHILL, and Terra Drone represent Japan's hybrid ecosystem where established manufacturers provide hardware scale while startups drive software innovation in orchestration and automation.

Bernie Sanders vs. the AI Billionaires
Bernie Sanders says AI billionaires are building a surveillance state and coming for your job. His new WSJ OpEd pulls no punches.

Noah Smith: AI Replaces Tasks, Not Jobs
Noah Smith argues that AI replaces tasks while leaving jobs intact. His framework explores how workers adapt through specialization, generalist flexibility, or AI-powered solo operations.

Copilot is 'for entertainment purposes only' in Microsoft terms
Microsoft's Copilot terms state the AI is 'for entertainment purposes only' and warn against relying on it for important advice. A spokesperson called this 'legacy language' that will be updated. OpenAI and xAI have similar disclaimers, categorizing AI outputs as non-professional opinion rather than actionable advice.
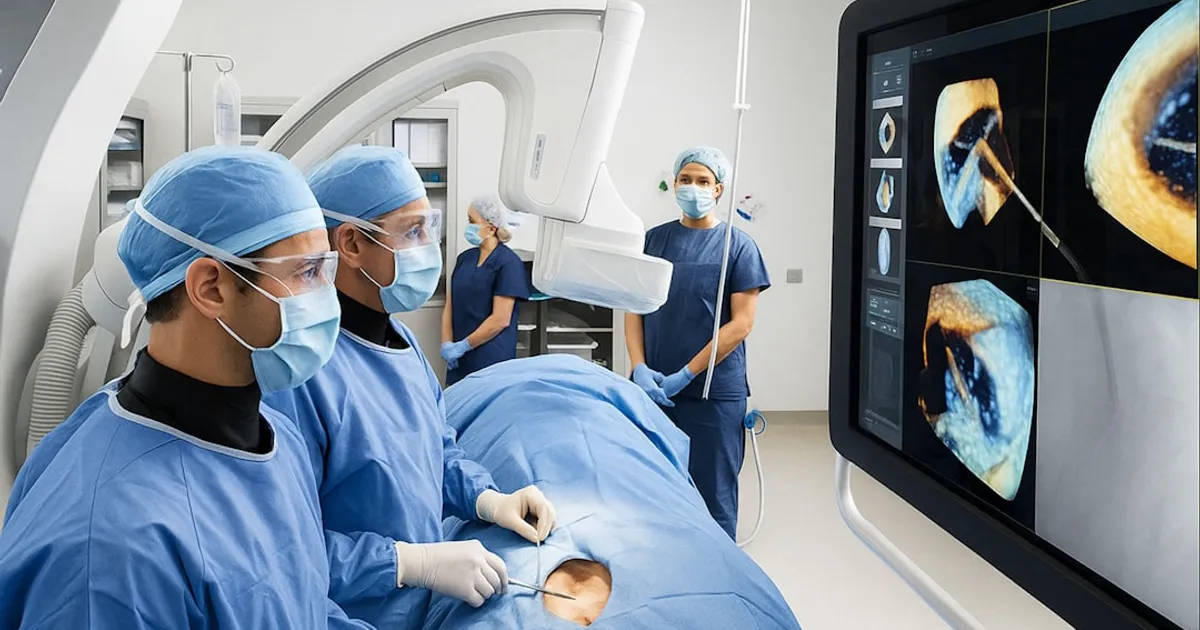
Cancer Patients Cut MRI Time by 60% in Amsterdam AI Trial
Amsterdam's Antoni van Leeuwenhoek Hospital has deployed AI software that shortens MRI scans from 23 to 9 minutes. The Philips-developed system predicts missing image data, letting radiologists work with fewer scan passes. The hospital now runs 18 extra scans weekly, and image quality has improved because shorter scans capture less motion blur from patients breathing and shifting.
Modo: Open-Source AI IDE That Plans First, Codes Second
Modo is an open-source AI IDE built on top of the Void editor (a VS Code fork) that implements spec-driven development workflows. It features prompt-to-requirements-to-design-to-tasks-to-code pipelines, task management with CodeLens integration, steering files for project rules, agent hooks for automation, autopilot/supervised modes, parallel chat sessions, and subagents. Built with TypeScript and React, it supports multi-provider LLMs (Anthropic, OpenAI, Gemini, Ollama, Mistral, Groq, OpenRouter) and MCP integration.

Modo: Open-source AI IDE with spec-first approach
Modo is an open-source AI coding IDE built on top of Void (a VS Code fork) that offers spec-driven development, agent hooks, subagents, task management, steering files, and parallel chat sessions. It positions itself as an alternative to commercial AI coding tools like Cursor, Windsurf, and Kiro.

Runway's GEN-1 Nails Laundry Folding. The Name? Not So Much.
An announcement/demo of Runway's GEN-1 video generation model. Comments mention an impressive demo featuring realistic laundry folding animation and note the generic naming.

South Korea's government buys AI bears for lonely seniors
The elderly companion robot market is splitting into distinct camps: South Korea's government-subsidized AI bears, $6,000 therapeutic seals for dementia care, and direct-to-consumer robot pets from a Hasbro spinoff. The approaches vary wildly in price and positioning, but evidence on whether they actually reduce loneliness remains thin.

Good Writing Now Gets You Accused of Being AI
An Ask HN discussion exploring methods for detecting AI-generated text. Commenters debate the reliability of detection systems, noting common stylistic markers like bullet points, em dashes, and certain words (e.g. 'Delve', 'Vibrant', 'Additionally'). The consensus is that reliable detection is nearly impossible due to the arms race between detectors and AI, and that approaches differ based on goals (spam prevention vs. discouraging copy-pasting). Some suggest that accusations of AI writing have ironically become a sign of high-quality human writing.

Microsoft's Copilot Terms Call It 'Entertainment Only'
Microsoft's terms of use state Copilot is 'for entertainment purposes only' and warn against relying on it for important advice. A company spokesperson called this 'legacy language' that will be updated to reflect how people actually use the AI assistant today.
8 Years Stuck, 3 Months Shipping, Then a Full Rewrite
Lalit Maganti wanted to build SQLite devtools for eight years. He shipped syntaqlite in three months using Claude Code, Aider, and Roo Code. The project required reverse-engineering SQLite's C source. AI agents helped him push past inertia and generate boilerplate. By late January he had a working parser, formatter, and 500 tests. Then he threw it away. The codebase was spaghetti. He rewrote everything in Rust, using AI as 'autocomplete on steroids' rather than delegating to it. AI got the project unstuck. Someone still needed to understand what got built.

Explosive News: The Lego-Style Propaganda Channel Iran Loves
The article profiles 'Explosive News' (Akhbar Enfejari), a YouTube channel that creates AI-generated animated propaganda videos using Lego-style animations depicting political content. The videos feature anti-US and anti-Israel messaging, have been shared by Iranian government accounts and Russian state media, and have gone viral with millions of views. The group claims to be an independent student-led media team, though there are suspected ties to the Iranian regime. The article discusses 'slopaganda' - the intersection of generative AI and propaganda - as a new form of quickly produced, personalized political content.
AI Agents Can Now Hunt Award Flights Across 25 Programs
A toolkit providing MCP servers and skills that enable AI agents like Claude Code and OpenCode to perform autonomous travel planning tasks including award flight searches across 25+ programs, cash price comparisons, loyalty balance checking, and booking recommendations.

Linux Kernel Security Reports Jump from 3/Week to 10/Day
Linux kernel developer Willy Tarreau reports security bug submissions have jumped from 2-3 per week to 5-10 per day. Unlike the previous wave of low-quality AI-generated reports, most current reports are accurate, forcing the team to recruit additional maintainers. Tarreau predicts this will end security embargoes and force projects toward continuous maintenance.
AMD's Lemonade: Local AI Server That Actually Works on AMD Hardware
Lemonade is an open-source local AI inference server backed by AMD, designed to run text, image, and speech models on PCs using GPU and NPU acceleration. It features a lightweight 2MB C++ backend, one-minute installation, OpenAI API compatibility for integration with hundreds of apps, and supports multiple inference engines including llama.cpp and Ryzen AI SW.

Sakana's AI Scientist Cleared NeurIPS Peer Review
Presents 'The AI Scientist,' a pipeline that automates the entire scientific research cycle from idea generation to peer review using foundation models and agentic systems. The system can create research ideas, write code, run experiments, analyze data, write manuscripts, and perform peer review. One generated manuscript passed the first round of peer review for a top-tier ML conference workshop.

AMD's Lemonade: Local LLM Server That Actually Works on Radeon
Lemonade is AMD's open-source local LLM server supporting GPU and NPU for text, image, and speech generation. It offers OpenAI API compatibility, runs on Windows/Linux/macOS, and works with llama.cpp and Ryzen AI SW engines.

Lisp Devs Pay More for AI Help, and Training Data Is to Blame
A DevOps engineer burned $20 watching AI struggle with Lisp, then switched to Python and finished in a day. REPL workflows break how AI agents operate, and sparse training data makes Lisp economically impractical for AI-assisted coding. Language choice has always mattered. Now it hits your wallet too.

The PhD Trap: AI Agents vs Real Understanding
An essay examines how AI agents risk producing researchers who generate output without developing genuine understanding. Through two hypothetical PhD students—one learning through struggle, one using AI—the author argues the technology accelerates production but bypasses learning. Cites David Hogg's astrophysics education work and Matthew Schwartz's Claude supervision experiment.
IsMCPDead.com Tracks MCP Adoption in Real Time
A live dashboard (ismcpdead.com) that tracks the adoption and sentiment of the Model Context Protocol (MCP), a standard for connecting LLMs to external tools and data. HN discussion highlights MCP's benefits for granular tool permissions compared to CLI apps, though notes token overhead as a potential downside.

Copilot's Fine Print: Entertainment Only, Not for Real Work
Microsoft's updated Copilot Terms of Use state the AI is designed for entertainment only and users should not rely on it for important advice, contrasting with the company's aggressive business marketing. Similar disclaimers exist across AI services including xAI, while real-world incidents like AWS outages from AI coding bots highlight reliability concerns.

Banray.eu: Why always-on AI glasses are a terrible idea
A critical awareness campaign highlighting serious privacy and safety concerns with Meta's Ray-Ban Meta smart glasses. The campaign exposes how footage is sent to human reviewers in Kenya without consent, details Meta's planned 'Name Tag' facial recognition feature, and warns about an entire industry converging on surveillance through smart glasses from Apple, Google, and Samsung.
Codex Goes Token-Based: What Developers Pay Now
OpenAI has transitioned Codex pricing from per-message to token-based usage for ChatGPT Business and new Enterprise customers. Credits are now calculated per million input tokens, cached input tokens, and output tokens for models including GPT-5.4, GPT-5.3-Codex, and GPT-5.1-Codex-mini. Legacy per-message pricing remains in effect for Plus/Pro customers and existing Enterprise/Edu plans until migration.

Caveman: Claude skill cuts LLM tokens by 75%
Caveman is a Claude Code skill that formats LLM output in simplified 'caveman' speech, reducing token usage by approximately 75% while maintaining technical accuracy. It removes filler words, articles, pleasantries, and hedging while preserving code blocks, technical terms, and error messages. The skill can be triggered with commands like '/caveman' or 'talk like caveman'. HN comments debate whether token reduction impacts LLM reasoning quality, noting that tokens are units of thinking for LLMs.

Nanocode: Train Your Own Claude Code Agent for $200
A GitHub project from Salman Mohammadi showing how to train your own Claude Code-like coding agent using Constitutional AI, JAX, and TPUs. Adapted from Andrej Karpathy's nanochat, it trains a 1.3B parameter model in ~9 hours for $200. Includes special tokens for tool calling with Read, Edit, and Grep tools for UNIX environments.
LM Studio 0.4.0 Adds Headless CLI: Gemma 4 at 51tps
A technical guide on running Google's Gemma 4 26B mixture-of-experts model locally on macOS using LM Studio 0.4.0's new headless CLI with Claude Code integration. Covers installation, benchmarks, performance tuning, and the new llmster daemon.

DRAM Market Splits: Samsung's 30% Hike vs. Falling Retail
Samsung locked in a 30% DRAM price hike for Q2 2026 contracts while retail and secondary market prices dropped 10-20%. The gap stems from hyperscalers spending $600 billion on AI infrastructure and claiming wafer capacity, Asian spot markets flushing inventory, and 'inference inversion' driving DDR4 and DDR5 prices in opposite directions depending on the sales channel.

Docker Offload GA: Run Containers in the Cloud When Your Laptop Can't
Docker announces general availability of Docker Offload, a fully managed cloud service that moves the container engine to Docker's secure cloud. Developers can run Docker from constrained environments like VDI platforms and locked-down laptops without changing workflows. The service offers multi-tenant and single-tenant deployment options with SOC 2 certification. Planned features include GPU-backed instances for AI/ML workloads, CI/CD integration, and BYOC deployment options.

Claude Code's Urgency Problem: 64 Failures, One Root Cause
A detailed case study analyzing Claude Code's reliability in maintaining a live show auto-polling feature, documenting 64 incidents across five failure modes. The author finds that AI agents prioritize immediate visible progress over process correctness under perceived urgency, violating established rules. The article concludes that mechanical mitigations (hooks, CI gates, tests, database constraints) are more effective than rules or memory for preventing AI agent failures.

Async Python Is Secretly Deterministic
This article explains how DBOS implemented deterministic async Python workflows for their durable execution library. It details how the asyncio event loop's FIFO scheduling order allows step IDs to be assigned deterministically before the first await, enabling concurrent workflows that can be reliably replayed during recovery. HN comments debate whether this behavior is guaranteed by the spec or just an implementation detail.

Qwen-3.6-Plus Just Hit 1.4T Tokens in a Day, 7x Its Rival
OpenRouter announced that Qwen-3.6-Plus has become the first model to process over 1 trillion tokens in a single day, a first for LLM infrastructure. The achievement, shared via Twitter, sparked comparisons to the 'DeepSeek moment' from earlier this year.
The functional programming fix for broken AI agents
This article argues that AI agents fail in production because codebases weren't built for them. The author proposes functional programming principles (formalized as SUPER and SPIRALS frameworks) to eliminate mutable state, hidden dependencies, and side effects that make agent output non-deterministic and impossible to debug. Code examples in multiple languages demonstrate refactoring from problematic to agent-friendly code.

ctx unifies Claude Code and Cursor in one containerized workspace
ctx is an Agentic Development Environment (ADE) that provides teams with a unified interface for managing multiple coding agents like Claude Code and Cursor. It features containerized workspaces with disk and network isolation, unified review surfaces for transcripts and diffs, and supports local or remote execution. The platform allows engineers to use preferred agents while giving security teams one controlled runtime with safety controls.

The Invisible Blast Radius Breaking Your AI Agents
This article argues that AI agents fail in production because codebases aren't built for them - with mutable state, hidden dependencies, and entangled side effects making agent output non-deterministic. The author proposes functional programming principles (formalized as SUPER - five code principles, and SPIRALS - a seven-step process loop) as a solution to make codebases more agent-friendly and enable deterministic, debuggable AI-generated code.

Async Python Is Secretly Deterministic
DBOS explains how they implemented deterministic async Python execution for their durable workflow library by exploiting the event loop's FIFO scheduling. The @Step() decorator assigns step IDs deterministically before the first await, enabling replay-based recovery for concurrent workflows. HN comments note this is an implementation detail of stdlib asyncio, not guaranteed by the spec.

Imbue throws 100 Claude agents at their testing problem
Imbue uses their tool mngr to orchestrate 100+ parallel Claude agents for automated testing. Tutorial scripts become pytest functions, testing agents run and debug each one, and a map-reduce pattern integrates results. The approach shows how composability and scalability let the same tool work at small local scales and large remote scales.

Ownscribe Runs Meeting Transcription Locally, No Cloud Required
Ownscribe is a local-first meeting transcription and summarization CLI tool that records, transcribes, and summarizes meetings entirely on your machine. It uses WhisperX for fast speech-to-text with word-level timestamps, supports speaker diarization via pyannote, and uses local LLMs like Phi-4-mini, Ollama, or LM Studio for structured meeting summaries. The tool features system audio capture on macOS 14.2+, natural-language search across meeting notes, and customizable summarization templates.

Imbue's 100-agent testing swarm finds bugs by watching AI fail
Imbue uses their 'mngr' tool to run 100+ Claude agents in parallel for automated testing. The workflow converts tutorial scripts to pytest functions, assigns an agent to each test, and merges results into a single PR. mngr handles both local development and remote execution on Modal.

Apfel exposes the AI model hiding on your Mac
Apfel is a free tool that exposes Apple's on-device LLM (Apple Foundation Model) by providing three interfaces: a CLI tool, an OpenAI-compatible HTTP server, and an interactive chat. It runs 100% locally on Apple Silicon Macs with macOS 26+, requires no API keys or subscriptions, and features native MCP (Model Context Protocol) support for tool calling across all modes.

OpenRouter Hits Unicorn Status as AI Model Chaos Fuels Demand
OpenRouter, a platform that helps companies access and switch between various AI models, has raised $120 million in funding at a $1.3 billion valuation. The service acts as a proxy/middleware layer for model routing and selection, similar to Google's VertexAI but as an independent aggregator.

Running Gemma 4 on Mac mini: Skip the 26B Model
A setup guide for running Ollama with Gemma 4 on Apple Silicon Mac minis. The practical advice: with 24GB RAM, use the 8B variant. The 26B model will eat your memory and trigger swapping. Covers installation, auto-start setup, and Ollama v0.19+ MLX acceleration. Gemma 4 has stability issues though. Some developers switched to Qwen.

Eight years of wanting, three months of building with AI
The author shares their experience building syntaqlite, a SQLite developer tool, over three months using AI coding agents. They discuss how AI helped overcome procrastination, accelerated code generation, acted as a teaching assistant, and enabled shipping more features than would have been possible alone. The article also covers the downsides including the addictive nature of AI tools and the importance of maintaining architectural oversight.

NHS staff refuse Palantir data platform over defense ties
NHS staff are reportedly refusing to use the Federated Data Platform (FDP) due to ethical concerns about its provider, Palantir. Palantir was awarded a £330 million contract in 2023 to collate operational data including patient information and waiting lists. Despite resistance, 123 of 205 hospital trusts in England are currently using the FDP. The government faces pressure from MPs and medical unions to trigger a contract break clause.

DocMason keeps your files local while making them AI-readable
DocMason is a repo-native agent app for deep research over private work files. It builds a local, evidence-first knowledge base with provenance, compiling private decks, spreadsheets, PDFs, and emails into structured, multimodal evidence bundles that AI agents can reason over. The tool runs entirely locally with no cloud ingestion, maintaining strict source identity and traceable answers.

AI's RAM Hunger Is Starving PC Builders
AI companies are buying up global RAM supply to power AI networks, causing prices to jump 3-6x. PC builders, gaming consoles, phones, and more are feeling the squeeze. New production won't arrive until 2028.

Claude Can Now Search Award Flights Across 25+ Airlines
An open-source toolkit that integrates with AI coding tools (Claude Code and OpenCode) via MCP servers and skills to enable AI-assisted travel hacking. It allows users to search award availability across 25+ mileage programs, compare points vs cash prices, check loyalty balances, and plan trips with real-time data from travel APIs like Seats.aero, Skiplagged, Kiwi, Trivago, Airbnb, and more.
Claude gets points-and-miles search skills with this toolkit
AI-powered travel hacking toolkit providing drop-in skills and MCP servers for OpenCode and Claude Code. Enables autonomous trip planning, points/miles management, award flight search across 25+ programs, cash price comparison, and loyalty balance tracking to help users decide whether to burn points or pay cash.
ctx unifies Claude Code, Cursor, Codex in one workspace
ctx is an Agentic Development Environment (ADE) that provides a unified interface for teams using multiple coding agents like Claude Code and Cursor. It features containerized workspaces with disk and network isolation, a unified review surface for tasks and transcripts, and an agent merge queue for managing parallel work across multiple worktrees.

Anthropic's 'free' credits have strings attached
Anthropic is offering a one-time extra usage credit to Pro, Max, and Team plan subscribers to celebrate the launch of usage bundles. Credits range from $20 for Pro plans to $200 for Team plans. Users must claim the credit by April 17, 2026, and it expires 90 days after claiming. HN comments indicate some users are experiencing issues claiming the credit, with speculation about additional unstated eligibility requirements and concerns about capacity issues causing delays in Claude Code.